Works with your existing systems
Madrona connects to the systems you already have - on the way in, on the way out, and across institutional boundaries. Integration is part of implementation, not a separate product to buy.
Discuss your integration needs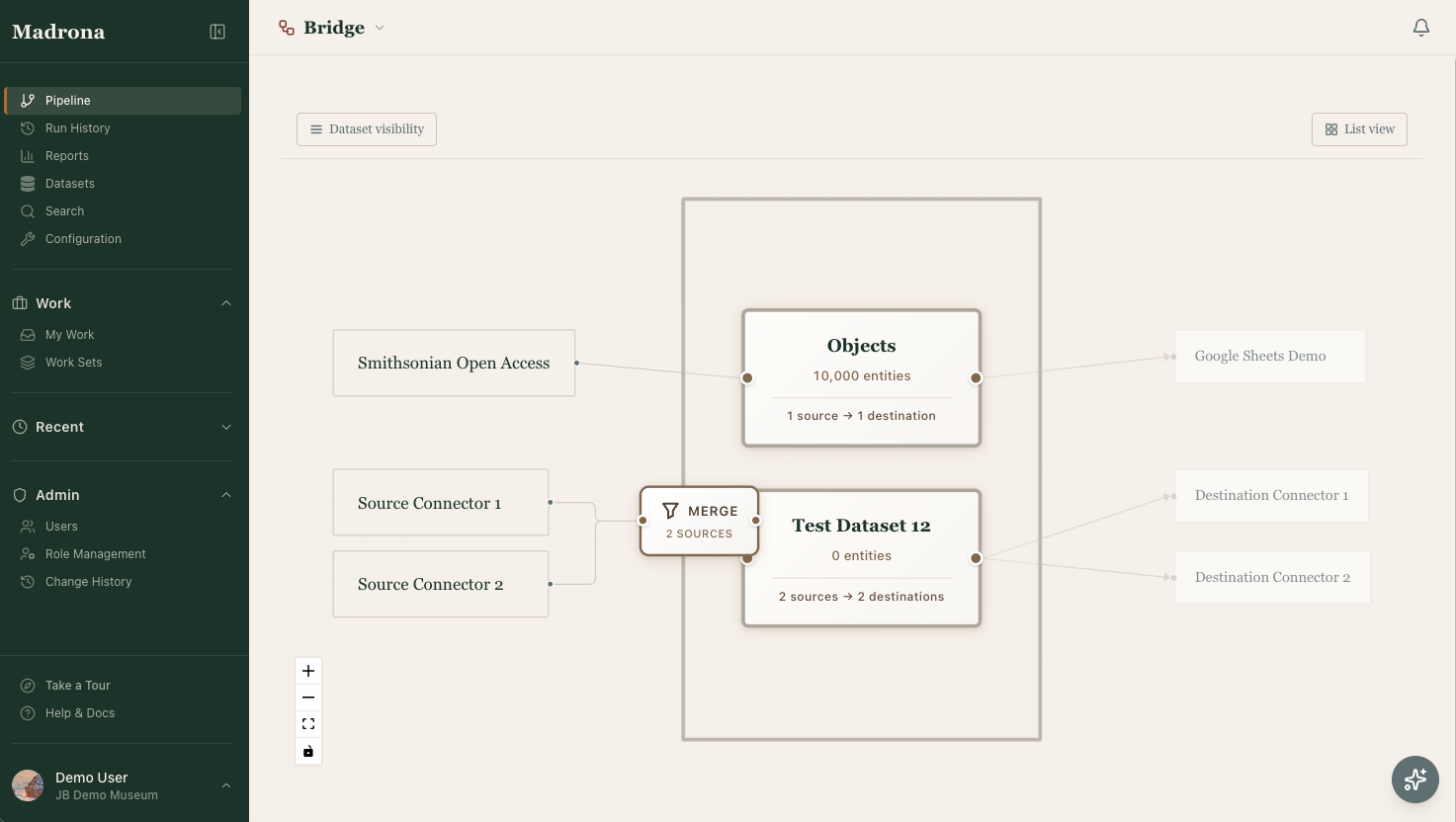
How integration works
Integration is scoped during discovery, configured during implementation, and maintained as part of your subscription. No separate product, no per-connection fees.
- 1
Discovery
We map your current systems, data structures, and ongoing workflows. Output: a written integration plan with field mapping, scope, and timeline.
- 2
Mapping
We design the field-by-field mapping between your source systems and Madrona, including controlled-vocabulary reconciliation against Getty AAT, ULAN, and TGN.
- 3
Extraction
We connect to the underlying database, API, or file export and pull data with full validation - record counts, integrity checks, and a discrepancy report.
- 4
Cutover
We migrate with parallel running where needed, so your team can validate Madrona against the legacy system before shutting it off.
- 5
Ongoing sync
For systems that stay in place, we configure scheduled or event-driven synchronization with conflict resolution and an audit trail.
Systems we migrate from
Legacy collection management and digital asset systems we connect to during implementation.
- TMS / TMS Collections (Gallery Systems)
- PastPerfect
- Axiell EMu, Adlib & Axiell Collections
- Vernon CMS & eHive
- MuseumPlus (zetcom)
- Re:discovery Proficio
- Mimsy XG
- Argus (Lucidea)
- CollectiveAccess
- Collector Systems
- ResourceSpace & other digital asset managers
- FileMaker, Access & spreadsheet databases
- Custom and homegrown systems
This is a representative list, not a limit. If your system is not here, we scope it during discovery - we connect to the underlying database, API, or file export.
Generic connectors
Beyond museum-specific systems, Madrona connects to standard infrastructure.
- Postgres, MySQL, SQL Server, SQLite
- REST and GraphQL APIs
- CSV, Excel, JSON, and JSON-LD imports and exports
- Amazon S3 and S3-compatible object storage
- Azure Blob Storage and Google Cloud Storage
- SFTP and HTTPS file drops
- IIIF endpoints (image servers and manifest providers)
Two-way and ongoing sync
Migration is the most common case, but not the only one. For institutions keeping a legacy system in production alongside Madrona, ongoing synchronization is configured during implementation.
Scheduled sync
Pull or push at configurable intervals - daily, hourly, or on demand.
Parallel running
During cutover, both systems stay live with reconciliation reports flagging drift.
Conflict resolution
Configure source-of-truth rules per field - Madrona wins, source wins, or flag for human review.
Audit trail across systems
Every sync action recorded with direction, fields touched, and outcome.
Data out
Your collection data does not stop at Madrona. We expose it to the aggregators, partner institutions, and adjacent systems you need to feed.
Aggregators and harvesters
JSON-LD exports and standards-compliant metadata for linked-data consumers and harvesters.
Federated search
IIIF Presentation manifests and schema.org markup that partner institutions and search engines can index.
Membership and donor systems
API integration with CRM and giving systems, scoped during implementation.
Analytics and reporting
Event streams and exports for analytics platforms and data warehouses.
Existing institutional websites
Madrona Content publishes directly. For institutions on a separate site, an embeddable widget and the public collection API surface your records.
Standards and protocols
Native support for the cultural-heritage interoperability standards your institution depends on.
IIIF
Image API 3.0 and Presentation API 3.0 for image serving and manifest generation. Compatible with Mirador and Universal Viewer.
JSON-LD
Linked-data export using schema.org, Dublin Core, and Getty vocabulary URIs. Suitable for CIDOC-CRM mapping.
Getty Vocabularies
Live SPARQL integration with AAT, ULAN, and TGN. Authority records resolved as you type.
Dublin Core
Dublin Core metadata export for harvesters and interoperability.
CDWA
Categories for the Description of Works of Art, native to the Madrona data model.
Schema.org
Structured data markup for search-engine discoverability and linked-data harvesters.
The Madrona API
Every integration sits on a documented REST API. If we have not built what you need, you can build it yourself.
REST API
Full CRUD coverage of objects, media, content, loans, exhibitions, locations, and more. JSON in, JSON out.
OpenAPI specification
Machine-readable spec for generating clients in any language.
Authentication
API keys with scoped permissions - read-only, full, or custom field-level. All access logged.
Rate limiting
Generous defaults with per-organization custom limits available on request.
Public collection endpoint
A separate read-only API for public collection access, configurable per field for exactly what is exposed.
Integrations for Guide
Madrona Guide speaks the Model Context Protocol (MCP). Connect AI clients like Claude Desktop or Cursor to your collection, and plug your own reference materials, partner APIs, and specialized vocabularies into Guide - no backend code changes.
Ready to connect your systems?
Tell us what you have. We will scope the integration as part of your implementation.
Request a demo